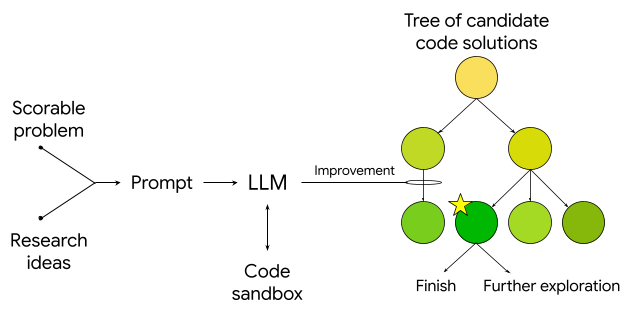
Google Research Scientists Leverage Empirical Research Assistance for Advanced Data Mining and Modeling
Google Research has highlighted the strategic implementation of Empirical Research Assistance by its scientists, focusing on the core disciplines of Data Mining and Modeling. According to the Google Research Blog, these methodologies are being utilized in four distinct ways to enhance the empirical research process. By integrating assistance tools into scientific workflows, researchers aim to improve the efficiency and accuracy of data-driven discoveries. This approach underscores a significant shift in how large-scale datasets are analyzed and how predictive models are constructed within high-level research environments. The focus remains on utilizing these computational techniques to provide robust empirical support for scientific inquiry, ensuring that data mining and modeling remain at the forefront of modern research assistance.
Key Takeaways
- Google Research scientists have identified four primary ways to utilize Empirical Research Assistance in their scientific workflows.
- The core technical focus of these assistance methods lies within the fields of Data Mining and Modeling.
- The integration of these tools is designed to streamline empirical research and improve the extraction of insights from complex datasets.
- This development highlights Google's commitment to advancing the methodology of empirical science through computational assistance.
In-Depth Analysis
The Framework of Empirical Research Assistance
Empirical Research Assistance represents a specialized approach to scientific inquiry at Google Research. By focusing on empirical methods, scientists are prioritizing evidence-based results derived from direct observation or experimentation. The title of the recent update from the Google Research Blog indicates that there are four specific ways this assistance is being applied. While the specific nuances of each way are rooted in the broader scientific process, the overarching goal is to provide a structured support system for researchers navigating the complexities of modern data environments. This assistance acts as a bridge between theoretical hypotheses and empirical validation, ensuring that the research conducted is both rigorous and reproducible.
Data Mining as a Research Catalyst
One of the central pillars mentioned in the context of this research assistance is Data Mining. In the realm of empirical research, data mining serves as the foundational process for discovering patterns and relationships within large sets of data. Google Research scientists utilize assistance tools to automate and refine these mining processes. By doing so, they can uncover hidden correlations that might be overlooked during manual analysis. This application of Empirical Research Assistance ensures that the data mining phase is not only faster but also more comprehensive, allowing scientists to handle the massive scales of information typical of modern AI and machine learning projects. The focus on data mining suggests that the "four ways" mentioned likely involve techniques for data cleaning, pattern recognition, and anomaly detection within empirical datasets.
The Role of Modeling in Empirical Assistance
Modeling is the second critical component identified in the scientists' use of Empirical Research Assistance. Modeling involves creating mathematical or computational representations of real-world systems to predict behavior or understand underlying mechanics. Within the framework of Google Research, modeling is used to test the patterns discovered during the data mining phase. Empirical Research Assistance helps scientists construct more accurate models by providing computational support and validation frameworks. This ensures that the models are grounded in empirical evidence and are capable of providing reliable predictions. The synergy between data mining and modeling, supported by research assistance, allows for a more iterative and robust scientific process where models are constantly refined based on new empirical data.
Industry Impact
The adoption of Empirical Research Assistance in the fields of data mining and modeling has significant implications for the broader AI and research industries. First, it demonstrates the increasing necessity of automated assistance in handling the sheer volume of data involved in contemporary research. As datasets grow, the ability of human researchers to perform exhaustive empirical analysis diminishes, making assistance tools vital. Second, by focusing on modeling, Google is reinforcing the importance of predictive accuracy in research. This shift toward assisted empirical research is likely to influence how other research institutions structure their workflows, potentially leading to a standardized model of "assisted science" where AI and computational tools are deeply integrated into every step of the empirical process. This could lead to faster breakthroughs in various fields, from machine learning to complex system modeling.
Frequently Asked Questions
Question: What are the primary domains where Google Research uses Empirical Research Assistance?
Based on the provided information, the primary domains are Data Mining and Modeling. These areas are essential for identifying patterns in data and creating predictive frameworks for scientific research.
Question: How many ways have Google Research scientists been using this assistance?
According to the Google Research Blog, scientists have been utilizing Empirical Research Assistance in four distinct ways, specifically focusing on enhancing their empirical research capabilities.
Question: What is the significance of combining data mining with modeling in this context?
Combining data mining with modeling allows researchers to first identify significant patterns within large datasets and then build frameworks to test and validate those patterns. Empirical Research Assistance streamlines this transition, making the scientific process more efficient and data-driven.