Meituan LongCat Team Launches LongCat-AudioDiT to Redefine Zero-Shot TTS Voice Cloning Limits
The Meituan LongCat team has officially unveiled LongCat-AudioDiT, a revolutionary Text-to-Speech (TTS) model designed to push the boundaries of zero-shot voice cloning. By fundamentally altering the synthesis pipeline, the model abandons traditional intermediate representations such as Mel-spectrograms. Instead, it operates directly within the waveform latent space using a diffusion-based framework. This strategic shift is intended to eliminate the cascade errors typically caused by multiple stages of data conversion. By allowing the AI to learn the inherent patterns and laws of sound directly, LongCat-AudioDiT aims to provide a more seamless and authentic voice cloning experience, addressing long-standing technical bottlenecks in the field of audio synthesis and zero-shot learning.
Key Takeaways
- Elimination of Intermediate Representations: LongCat-AudioDiT completely discards the use of Mel-spectrograms, a traditional staple in TTS pipelines.
- Direct Waveform Latent Space Processing: The model performs Text-to-Speech synthesis directly within the waveform latent space using diffusion models.
- Reduction of Cascade Errors: By removing intermediate steps, the architecture prevents the accumulation of errors that typically occur during data conversion stages.
- Zero-Shot Voice Cloning Breakthrough: The technology is specifically designed to overcome existing upper limits in zero-shot voice cloning performance.
- Focus on Sound Laws: The approach enables the AI to learn the underlying patterns of sound directly rather than relying on proxy representations.
In-Depth Analysis
The Shift from Mel-Spectrograms to Direct Waveform Synthesis
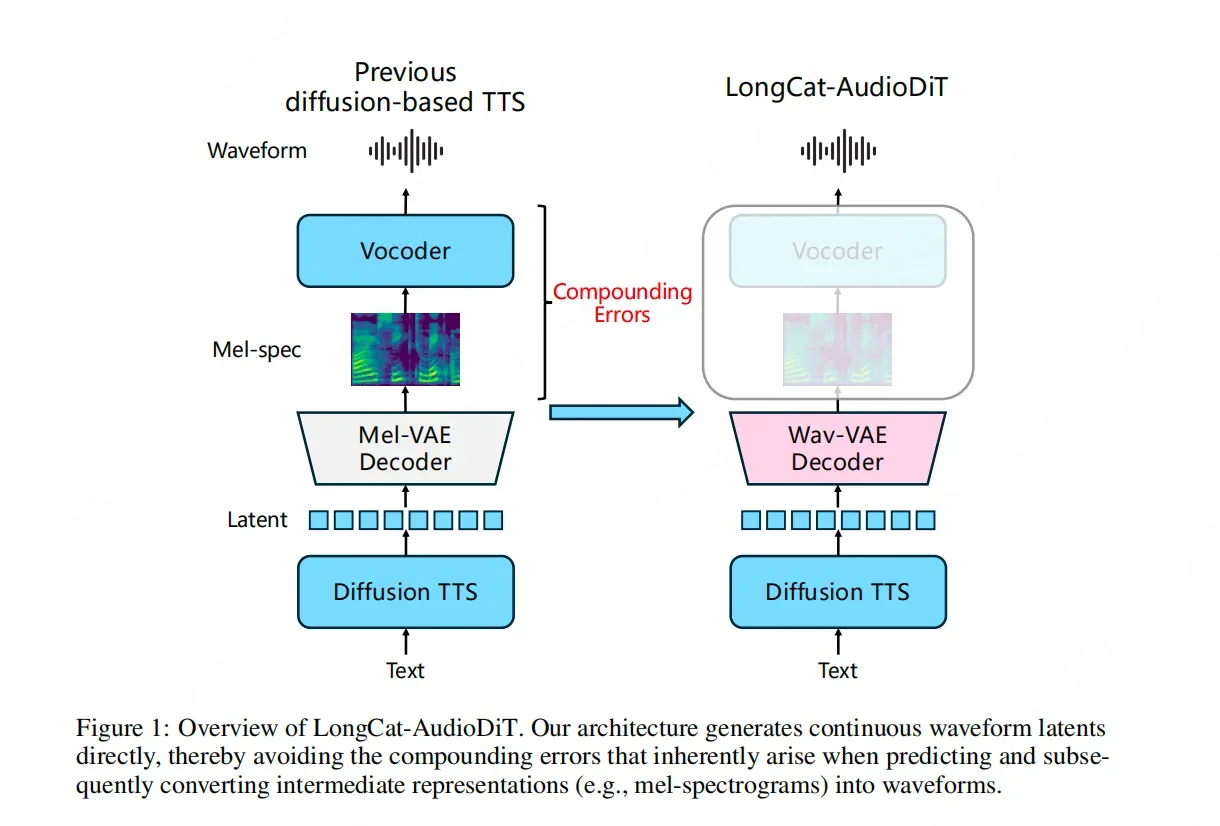
For years, the field of Text-to-Speech (TTS) has relied heavily on intermediate representations, most notably Mel-spectrograms. These representations act as a bridge between textual input and the final acoustic output. However, the Meituan LongCat team identified this bridge as a primary source of technical bottlenecks. In traditional systems, the conversion from text to Mel-spectrograms and then from Mel-spectrograms to raw audio (often via a vocoder) introduces what is known as "cascade errors." Each stage of conversion loses a degree of information and introduces artifacts, which ultimately limits the fidelity and authenticity of the cloned voice.
LongCat-AudioDiT represents a paradigm shift by "skipping the middleman." By abandoning Mel-spectrograms, the model removes the structural limitations inherent in these frequency-domain representations. The decision to operate directly in the waveform latent space allows the model to maintain a higher degree of data integrity. This approach ensures that the nuances of the original voice—essential for high-quality zero-shot cloning—are not lost in translation between different data formats.
Diffusion Models and the Waveform Latent Space
At the heart of LongCat-AudioDiT is the integration of diffusion models within a latent space specifically designed for waveforms. Diffusion models have gained prominence for their ability to generate high-quality, diverse data by reversing a noise process. By applying this logic to the waveform latent space, the LongCat team allows the AI to "learn the laws of sound itself."
This method allows the model to capture the complex, non-linear patterns of human speech more effectively than traditional autoregressive or GAN-based models might in a multi-stage pipeline. The "AudioDiT" nomenclature suggests a Diffusion Transformer architecture, which combines the generative power of diffusion with the scaling and attention capabilities of Transformers. This combination is leveraged to process the latent representations of audio directly, ensuring that the synthesized speech is not just a reconstruction of a spectrogram, but a direct manifestation of the learned acoustic patterns. This directness is what allows the model to break through the previous "upper limit" of zero-shot voice cloning, where the AI must mimic a voice it has never seen during training based on a very short sample.
Industry Impact
Setting a New Standard for Voice Authenticity
The introduction of LongCat-AudioDiT by Meituan signals a significant evolution in how the industry approaches audio synthesis. By proving that high-quality TTS can be achieved without intermediate representations, Meituan is challenging the standard architectural blueprints used by many AI research labs. This could lead to a broader industry trend where researchers prioritize "end-to-end" latent processing to minimize signal degradation. For applications requiring high-fidelity voice cloning—such as digital assistants, content creation, and personalized user interfaces—this technology offers a path toward near-perfect vocal mimicry.
Overcoming the Zero-Shot Bottleneck
Zero-shot voice cloning is one of the most difficult tasks in AI audio because it requires the model to generalize its understanding of speech to an entirely new identity instantly. By blocking the cascade errors that usually plague these systems, LongCat-AudioDiT provides a more robust framework for this generalization. As the AI industry moves toward more interactive and personalized experiences, the ability to clone voices accurately with minimal data and high reliability will become a competitive necessity. Meituan's research provides a technical roadmap for achieving this by focusing on the fundamental laws of sound rather than the limitations of legacy audio processing formats.
Frequently Asked Questions
Question: What is the main innovation of LongCat-AudioDiT?
The primary innovation is the total abandonment of intermediate representations like Mel-spectrograms. Instead, LongCat-AudioDiT uses diffusion models to perform Text-to-Speech synthesis directly within the waveform latent space, which prevents the accumulation of errors during data conversion.
Question: How does this model improve zero-shot voice cloning?
By operating directly in the waveform latent space, the model avoids "cascade errors"—the small mistakes that add up when converting audio between different formats. This allows the AI to capture the true essence and patterns of a voice more accurately, even when it has never encountered that specific voice before.
Question: Why did the Meituan team decide to skip the Mel-spectrogram stage?
The team identified that intermediate stages like Mel-spectrograms act as a technical bottleneck. Skipping these stages allows the AI to learn the inherent laws of sound directly from the source, leading to higher fidelity and a more efficient synthesis process that doesn't suffer from the losses associated with traditional data transformation.