LARYBench Released: A New Benchmark Defining the ImageNet for Embodied Action Representation and Generalization
The Meituan Technical Team has officially introduced LARYBench (Latent Action Representation Yielding Benchmark), a systematic evaluation framework designed to guide the learning of general latent action representations from large-scale visual data. Positioned as the 'ImageNet' for the embodied AI field, LARYBench provides a standardized way to measure how well models can understand and execute actions. The benchmark's initial experimental results reveal a significant shift in AI development: general-purpose vision models consistently outperform specialized embodied AI expert models in both action generalization and control precision. Furthermore, the research confirms that sophisticated embodied action representations can naturally emerge from training on extensive human video datasets, offering a scalable path for future robotic intelligence and autonomous systems.
Key Takeaways
- Introduction of LARYBench: A systematic benchmark designed to evaluate and guide the development of general latent action representations from visual data.
- Superiority of General Models: Experimental data indicates that general vision models outperform specialized embodied AI expert models in generalization and precision.
- Emergent Intelligence from Human Videos: The study proves that embodied action representations can emerge from large-scale human video data without specialized robotic training.
- New Industry Standard: LARYBench is being recognized as the 'ImageNet' for embodied action, providing a critical metric for the industry.
In-Depth Analysis
Establishing a Systematic Standard for Embodied AI
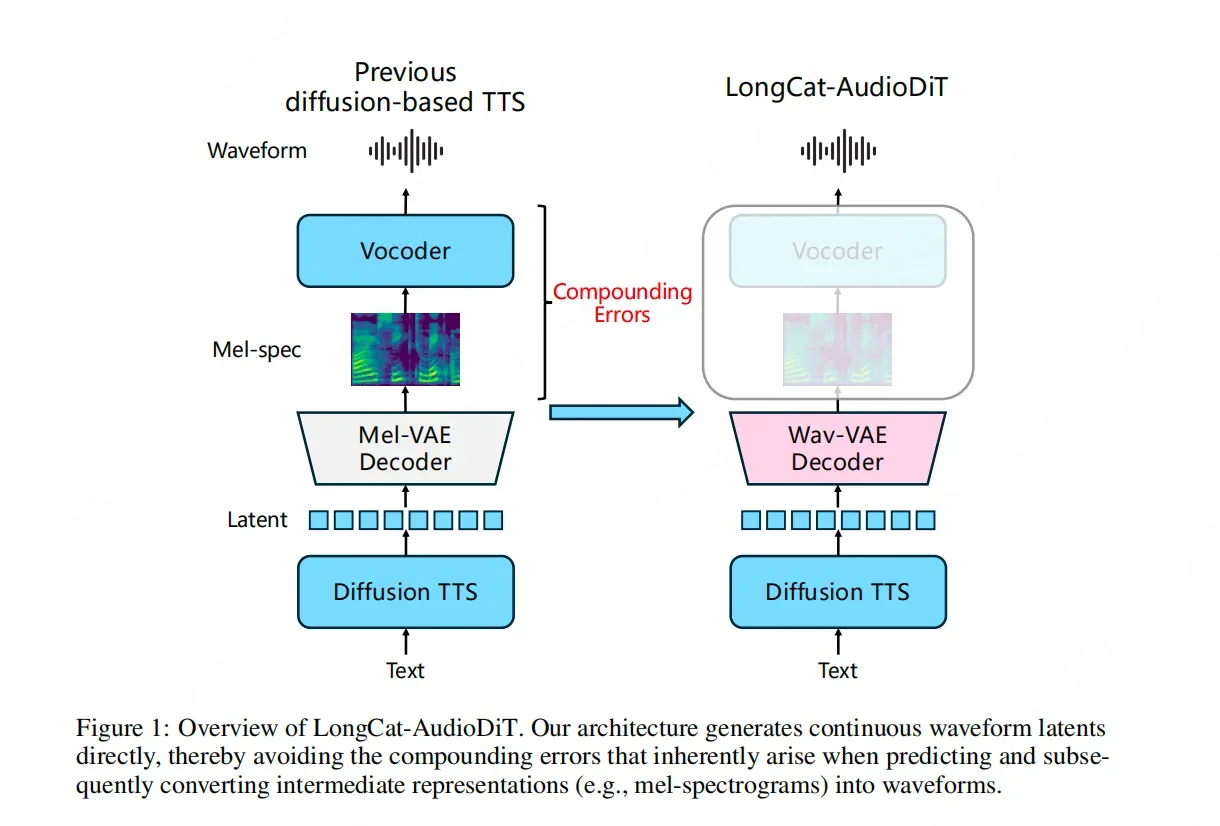
The release of LARYBench (Latent Action Representation Yielding Benchmark) marks a significant milestone in the evolution of embodied AI. Much like how ImageNet revolutionized computer vision by providing a massive, standardized dataset for object recognition, LARYBench aims to do the same for action representation. By focusing on "latent action representations," the benchmark moves beyond simple command-following and looks at the underlying structures of how an AI perceives and prepares to execute physical movements. This systematic approach allows researchers to evaluate how effectively a model can translate visual information into actionable intelligence, providing a clear roadmap for developing more versatile and capable autonomous agents.
General Vision Models vs. Specialized Action Experts
One of the most striking findings presented by the Meituan Technical Team is the performance gap between general vision models and specialized embodied action expert models. Traditionally, the industry has leaned toward creating "expert" models—AI systems specifically trained on robotic data to perform specific tasks. However, LARYBench's experimental results show that general vision models, which are trained on a much broader array of visual data, exhibit significantly better action generalization and control precision. This suggests that the breadth of information contained in general vision models provides a more robust foundation for physical interaction than the narrow, task-specific training of expert models. This finding could lead to a paradigm shift in how robotic controllers are designed, favoring large-scale general pre-training over niche specialization.
The Power of Large-Scale Human Video Data
The research highlights a critical breakthrough in data sourcing for embodied AI: the emergence of action representations from human video data. Previously, it was often assumed that to teach a robot how to move, one needed data specifically from robots (teleoperation or simulation). LARYBench demonstrates that by analyzing large-scale human videos, AI models can learn the nuances of movement, spatial relationships, and physical interaction. This "emergence" of embodied intelligence from non-robotic data sources is a game-changer for the industry. It suggests that the vast libraries of human video content available today can serve as a primary training ground for the next generation of embodied AI, drastically reducing the reliance on expensive and hard-to-collect robotic execution data.
Industry Impact
The introduction of LARYBench is expected to have a profound impact on the AI and robotics industries. By providing a standardized metric for action representation, it allows for more transparent comparisons between different AI architectures. The discovery that general vision models are superior for action generalization suggests that the future of robotics lies in the integration of Large Vision Models (LVMs) rather than isolated robotic controllers. Furthermore, the ability to leverage human video data for training opens the door for rapid scaling in embodied AI, potentially accelerating the deployment of autonomous systems in complex, real-world environments such as logistics, manufacturing, and domestic assistance.
Frequently Asked Questions
Question: What is the primary purpose of LARYBench?
LARYBench is a systematic evaluation benchmark designed to measure and guide the learning of general latent action representations from large-scale visual data, serving as a foundational tool for embodied AI development.
Question: Why are general vision models performing better than specialized models in this benchmark?
According to the research, general vision models demonstrate superior action generalization and control precision because they benefit from a broader understanding of visual contexts, which proves more effective for complex embodied tasks than the narrow training of specialized expert models.
Question: Can AI learn to control robots just by watching human videos?
Yes, the findings from LARYBench show that embodied action representations can emerge from large-scale human video data, suggesting that models can learn the fundamental principles of action and movement by observing human behavior at scale.