Meituan LongCat-AudioDiT: Redefining Zero-Shot Voice Cloning by Eliminating Intermediate Mel-Spectrogram Representations in TTS
Meituan's LongCat team has unveiled LongCat-AudioDiT, a novel model that advances the state of zero-shot Text-to-Speech (TTS) voice cloning. The core innovation lies in its departure from traditional intermediate representations, such as Mel-spectrograms, which often introduce cascade errors during the synthesis process. Instead, LongCat-AudioDiT utilizes a diffusion-based architecture that operates directly within the waveform latent space. By learning the fundamental patterns of sound without intermediate steps, the model aims to achieve higher fidelity and more accurate voice replication. This technical breakthrough addresses long-standing bottlenecks in audio generation, positioning LongCat-AudioDiT as a significant development in the field of AI-driven voice synthesis and zero-shot cloning technology.
Key Takeaways
- Elimination of Mel-Spectrograms: LongCat-AudioDiT removes the need for intermediate Mel-spectrogram representations, which are standard in traditional TTS pipelines.
- Direct Waveform Latent Space: The model operates directly within the waveform latent space to generate audio, reducing the complexity of the synthesis process.
- Diffusion-Based Architecture: It utilizes a diffusion model (AudioDiT) to learn the inherent laws of sound and voice patterns.
- Reduction of Cascade Errors: By bypassing intermediate stages, the model prevents the accumulation of errors that typically occur during data conversion between different stages of a TTS system.
- Zero-Shot Capability: The architecture is specifically designed to push the upper limits of zero-shot voice cloning, allowing for high-quality replication of unseen voices.
In-Depth Analysis
Moving Beyond Intermediate Representations
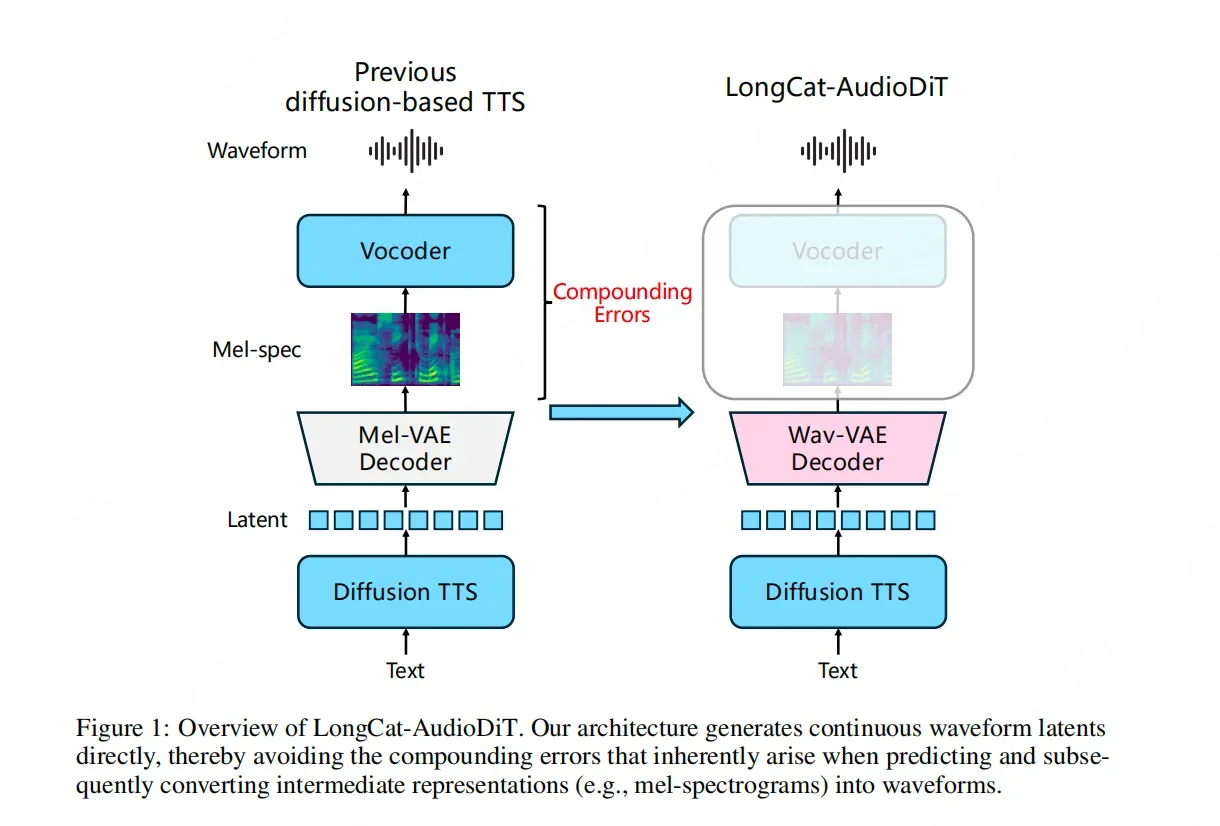
For years, the standard architecture for Text-to-Speech (TTS) systems has relied on a multi-stage process. Typically, a model first converts text into an intermediate representation, most commonly a Mel-spectrogram. A second model, known as a vocoder, then converts that Mel-spectrogram into a listenable audio waveform. While effective, this approach has a fundamental flaw: cascade errors. Errors introduced during the text-to-spectrogram phase are amplified during the spectrogram-to-waveform phase, often resulting in artifacts or a loss of naturalness in the cloned voice.
Meituan’s LongCat team has addressed this bottleneck with the introduction of LongCat-AudioDiT. The defining characteristic of this model is the complete abandonment of Mel-spectrograms. By removing this middleman, the model seeks to "directly learn the laws of sound itself." This shift represents a move toward a more end-to-end philosophy in audio generation, where the AI interacts more closely with the raw characteristics of the audio signal rather than a visual approximation of it.
The Power of Waveform Latent Space and Diffusion
LongCat-AudioDiT operates within the waveform latent space. In technical terms, this means the model works with a compressed, high-dimensional representation of the actual audio waveform rather than a frequency-domain representation like a spectrogram. By performing synthesis in this space, the model can capture the intricate nuances of a person's voice—such as timbre, breathiness, and prosody—more accurately than traditional methods.
Central to this process is the use of Diffusion Models (AudioDiT). Diffusion models have recently revolutionized image generation, and their application to audio is proving equally transformative. In LongCat-AudioDiT, the diffusion process iteratively refines noise into a clear audio signal within the latent space. This allows the model to generate high-fidelity audio that maintains the structural integrity of the original voice being cloned. Because the model is trained to understand the underlying patterns of sound directly, it can generalize better to new, unseen voices, which is the hallmark of "zero-shot" cloning.
Overcoming Technical Bottlenecks in Voice Cloning
The primary goal of LongCat-AudioDiT is to break the "upper limit" of zero-shot voice cloning. Zero-shot cloning is particularly challenging because the AI must replicate a voice it has never encountered during its primary training phase, often using only a very short sample of the target voice. Traditional models often struggle with this because the conversion to Mel-spectrograms loses critical phase information and fine-grained acoustic details.
By "blocking the cascade error from the source," LongCat-AudioDiT ensures that the data remains as pure as possible throughout the generation pipeline. This direct-to-waveform approach ensures that the subtle characteristics that make a human voice unique are preserved. The result is a system that doesn't just mimic the pitch and speed of a voice, but captures its essential "artistry" and identity, pushing the boundaries of what is possible in synthetic speech.
Industry Impact
The release of LongCat-AudioDiT by Meituan marks a significant shift in the AI audio landscape. By demonstrating that high-quality TTS can be achieved without intermediate Mel-spectrograms, Meituan is challenging the industry standard and paving the way for more streamlined, efficient audio models. This innovation has broad implications for various sectors:
- Content Creation: High-fidelity zero-shot cloning allows for more realistic dubbing and voice-over work without the need for extensive recording sessions.
- Human-Computer Interaction: Virtual assistants and AI agents can adopt more natural and diverse personas with minimal data input.
- Technical Efficiency: Reducing the number of stages in the TTS pipeline can lead to more robust models that are less prone to the "robotic" artifacts associated with traditional vocoders.
As diffusion models continue to mature, the transition to latent space audio generation is likely to become the new benchmark for excellence in the field of artificial intelligence.
Frequently Asked Questions
Question: What is the main difference between LongCat-AudioDiT and traditional TTS models?
Traditional TTS models usually convert text to a Mel-spectrogram first and then use a vocoder to create sound. LongCat-AudioDiT skips the Mel-spectrogram entirely and generates audio directly in the waveform latent space using diffusion models, which prevents errors from building up between stages.
Question: Why is the removal of Mel-spectrograms considered a breakthrough?
Mel-spectrograms are an approximation of sound that can lose important details. By removing them, the model avoids "cascade errors"—where mistakes in the first stage of generation affect the final output—resulting in a more accurate and natural-sounding voice clone.
Question: What does "zero-shot" mean in the context of LongCat-AudioDiT?
Zero-shot refers to the model's ability to clone a specific person's voice using only a short audio sample, even if the model was never specifically trained on that person's voice before. LongCat-AudioDiT aims to improve the quality and realism of these clones.