Meituan LongCat-AudioDiT: Redefining Zero-Shot TTS Voice Cloning via Waveform Latent Diffusion
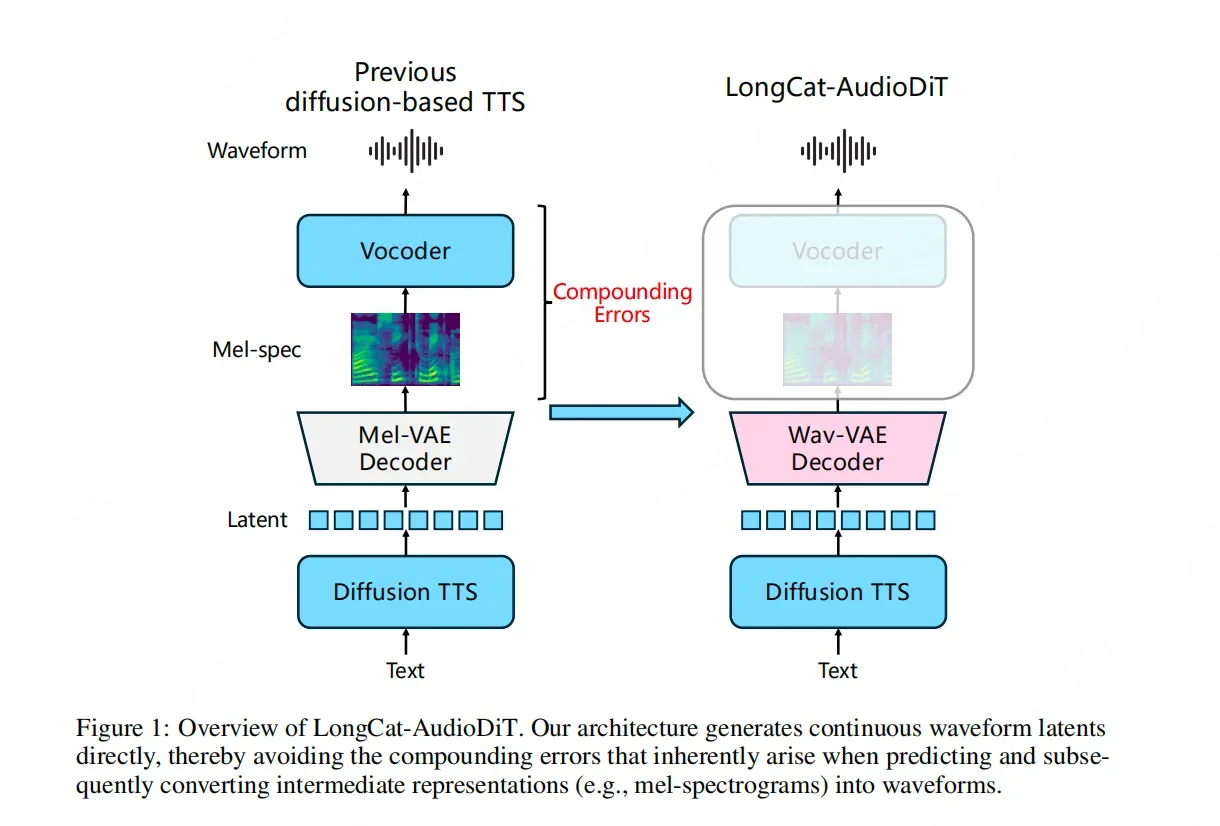
The Meituan LongCat team has officially unveiled LongCat-AudioDiT, a pioneering model designed to push the boundaries of zero-shot Text-to-Speech (TTS) voice cloning. By fundamentally reimagining the audio synthesis pipeline, the model abandons traditional intermediate representations like Mel-spectrograms in favor of direct operation within the waveform latent space. Utilizing a Diffusion Transformer (DiT) architecture, LongCat-AudioDiT aims to eliminate the cascade errors typically associated with multi-stage data conversion. This approach allows the AI to learn the intrinsic laws of sound directly, offering a more robust and high-fidelity solution for cloning voices without prior training on specific target speakers. The release marks a significant technical shift toward end-to-end waveform generation in the field of AI-driven speech synthesis.
Key Takeaways
- Direct Waveform Processing: LongCat-AudioDiT bypasses intermediate steps like Mel-spectrograms, operating directly in the waveform latent space.
- Zero-Shot Capability: The model is specifically designed to enhance the quality and authenticity of zero-shot voice cloning.
- Diffusion Transformer Architecture: It leverages a Diffusion Model (DiT) to synthesize speech, ensuring high-fidelity output.
- Error Reduction: By removing intermediate representations, the model effectively blocks cascade errors caused by data conversion processes.
In-Depth Analysis
Breaking the Bottleneck of Intermediate Representations
In traditional Text-to-Speech (TTS) systems, the process of generating human-like speech often involves several intermediate stages. The most common approach involves converting text into a Mel-spectrogram—a visual representation of the spectrum of frequencies of a signal as it varies with time—before using a separate vocoder to transform that spectrogram back into audible waveforms. While effective, this multi-step process introduces a significant technical bottleneck: cascade errors. Each stage of conversion can lose data or introduce artifacts, leading to a final output that may lack the nuance and clarity of the original target voice.
Meituan’s LongCat team addresses this bottleneck head-on with LongCat-AudioDiT. The core innovation of this model lies in its complete abandonment of Mel-spectrograms and other intermediate representations. Instead, the model is designed to let the AI directly learn the "laws of sound" by operating within the waveform latent space. By skipping the intermediate conversion steps, the model ensures that the relationship between the input text and the resulting audio is more direct and less prone to the cumulative inaccuracies that plague traditional TTS pipelines.
The Role of Diffusion Transformers in Waveform Latent Space
LongCat-AudioDiT utilizes a Diffusion Transformer (DiT) architecture to navigate the complexities of the waveform latent space. Diffusion models have recently become the gold standard for generative tasks due to their ability to produce high-quality, diverse outputs by iteratively refining noise into a structured signal. By applying this logic directly to the waveform latent space, LongCat-AudioDiT can capture the intricate patterns of human speech with higher precision than models constrained by the limitations of frequency-domain representations.
This technical choice is particularly critical for zero-shot voice cloning. In a zero-shot scenario, the model must replicate a voice it has never encountered during its primary training phase, based only on a short audio prompt. By operating in the latent space of the waveform itself, LongCat-AudioDiT can more accurately map the unique acoustic characteristics of a prompt voice to the synthesized speech, resulting in a clone that sounds more natural and maintains the specific timbre and prosody of the original speaker without the "robotic" artifacts often introduced by Mel-spectrogram-based synthesis.
Industry Impact
Setting a New Standard for Audio Fidelity
The introduction of LongCat-AudioDiT signals a potential shift in the AI industry’s approach to audio synthesis. By demonstrating that high-quality TTS can be achieved without relying on legacy intermediate representations, Meituan is setting a new benchmark for audio fidelity. This move toward "direct-to-waveform" latent processing could encourage other research teams to move away from the Mel-spectrogram paradigm, leading to a new generation of AI voice tools that are more expressive and less susceptible to conversion-related quality loss.
Advancing the Practicality of Zero-Shot Cloning
Zero-shot voice cloning is a highly sought-after capability for applications ranging from personalized digital assistants to content creation and localization. However, the utility of these applications is often limited by the "uncanny valley" effect—where the cloned voice sounds almost, but not quite, human. By blocking cascade errors at the source, LongCat-AudioDiT improves the reliability of zero-shot cloning, making it a more viable tool for commercial industries that require high-quality, instant voice replication without the need for extensive fine-tuning or large datasets for every new speaker.
Frequently Asked Questions
Question: What makes LongCat-AudioDiT different from traditional TTS models?
Traditional TTS models usually convert text to a Mel-spectrogram first and then use a vocoder to create sound. LongCat-AudioDiT skips these intermediate steps and generates speech directly in the waveform latent space, which reduces errors and improves sound quality.
Question: How does this model improve zero-shot voice cloning?
By operating directly on the waveform's latent patterns using a Diffusion Transformer, the model can more accurately capture and replicate the unique characteristics of a new voice from a small sample, avoiding the quality degradation that happens during data conversion in older models.
Question: What are "cascade errors" in the context of AI audio?
Cascade errors occur when a mistake or loss of detail in one stage of a process (like converting text to a spectrogram) is carried over and amplified in the next stage (like converting that spectrogram to sound). LongCat-AudioDiT eliminates these by using a more direct, single-path synthesis approach.