Meituan LongCat Team Launches LongCat-AudioDiT to Advance Zero-Shot TTS Voice Cloning via Waveform Latent Space
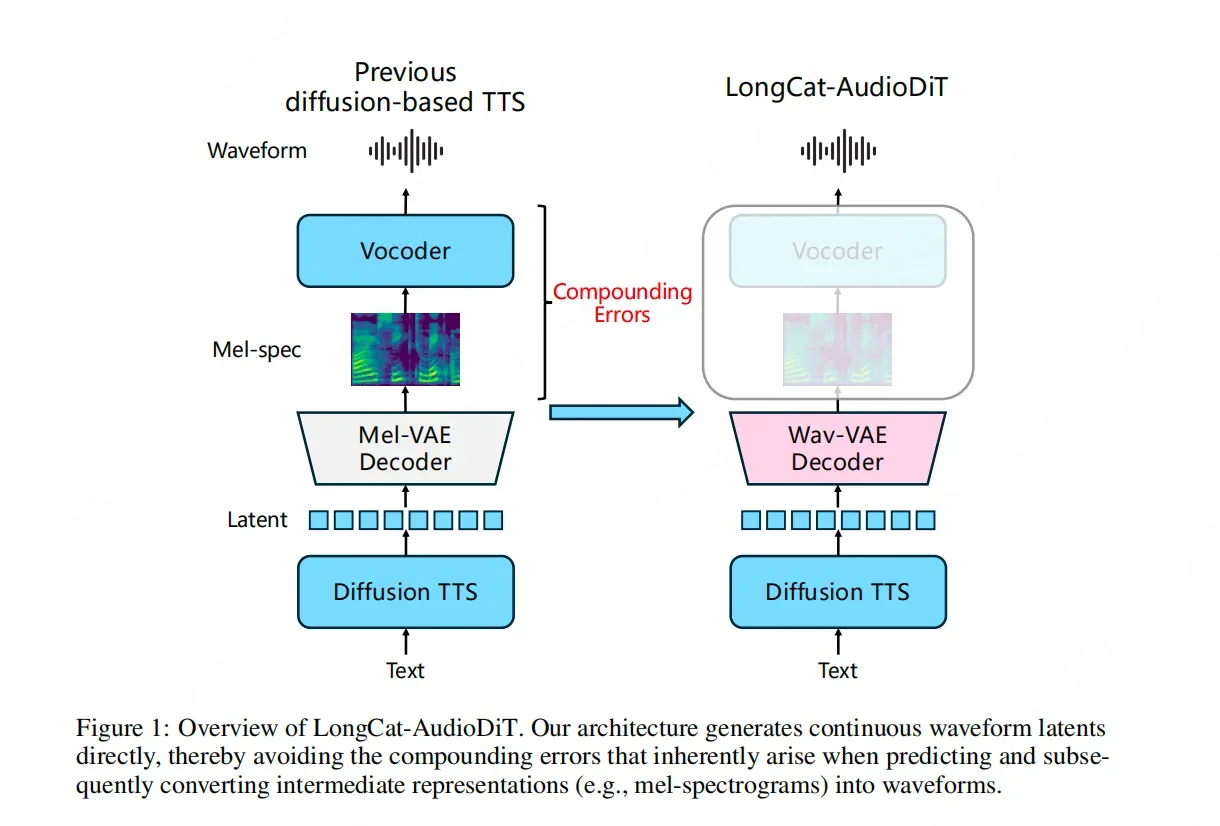
The Meituan LongCat team has officially released LongCat-AudioDiT, a pioneering model designed to redefine the boundaries of zero-shot Text-to-Speech (TTS) voice cloning. By moving away from traditional intermediate representations such as Mel-spectrograms, LongCat-AudioDiT operates directly within the waveform latent space using a diffusion-based approach. This architectural shift is specifically engineered to eliminate cascade errors typically associated with multi-stage data conversion processes. By enabling the AI to learn the inherent patterns and laws of sound directly, the model provides a more streamlined and accurate method for high-fidelity voice synthesis. This development represents a significant technical leap in achieving precise voice cloning without the need for extensive fine-tuning, addressing long-standing bottlenecks in generative audio technology.
Key Takeaways
- Direct Waveform Processing: LongCat-AudioDiT operates directly in the waveform latent space, bypassing traditional intermediate steps like Mel-spectrograms.
- Diffusion Model Integration: The system utilizes a diffusion-based approach to perform Text-to-Speech (TTS) synthesis, enhancing generative quality.
- Elimination of Cascade Errors: By removing intermediate data representations, the model prevents the accumulation of errors inherent in traditional conversion pipelines.
- Zero-Shot Breakthrough: The architecture is specifically optimized to push the performance limits of zero-shot voice cloning, requiring minimal source audio.
In-Depth Analysis
Bypassing Intermediate Representations
The core innovation of LongCat-AudioDiT lies in its fundamental departure from the standard Text-to-Speech (TTS) pipeline. Historically, the majority of TTS systems have relied on intermediate representations, most notably Mel-spectrograms, to bridge the gap between textual input and acoustic output. While effective, the Meituan LongCat team identified these intermediate steps as a primary source of technical bottlenecks. When data is converted from text to a spectrogram and then finally into a waveform via a vocoder, each transition introduces a margin of error. These are known as cascade errors, where inaccuracies in the first stage are amplified in subsequent stages. By "throwing away" the Mel-spectrogram entirely, LongCat-AudioDiT allows the AI to interact more directly with the audio data. This ensures that the subtle nuances, textures, and unique characteristics of a human voice are preserved without being lost or distorted during data format transitions.
Diffusion Models in the Waveform Latent Space
The implementation of a diffusion model within the waveform latent space represents a strategic shift in how artificial intelligence perceives and generates sound. Instead of attempting to map text to a visual proxy of sound, LongCat-AudioDiT focuses on the latent laws of the sound waves themselves. Diffusion models have gained prominence for their ability to generate high-quality, complex data by reversing a noise-injection process. When this mathematical framework is applied directly to the waveform latent space, it allows the model to reconstruct speech with a level of fidelity that traditional methods struggle to match. The LongCat team’s philosophy centers on letting the AI "directly learn the laws of sound itself." This approach simplifies the overall architecture while simultaneously increasing the potential for high-quality output, as the model deals with the raw essence of the waveform rather than a simplified, lossy representation.
Solving the Cascade Error Problem
The primary technical goal of LongCat-AudioDiT is to block cascade errors at the source. In traditional systems, the conversion from a Mel-spectrogram back to a waveform (often handled by a separate vocoder) is a reconstruction process that can never be 100% perfect. By performing the entire TTS process within the waveform latent space, Meituan has created a more unified and cohesive generation path. This direct-to-waveform approach means that the generative model has a more holistic understanding of the audio it is producing. For zero-shot voice cloning—where the AI must mimic a voice it has never seen before based on a very short sample—this reduction in error is critical. It allows the system to capture the fine-grained rhythms and emotional undertones of a voice sample more effectively, breaking the previous "upper limit" of what zero-shot cloning could achieve in terms of similarity and naturalness.
Industry Impact
The release of LongCat-AudioDiT by Meituan's technical team signals a significant evolution in the AI audio landscape. By demonstrating that high-quality, zero-shot TTS can be achieved without relying on intermediate representations, Meituan is challenging established industry standards. This breakthrough is likely to encourage a broader industry trend toward end-to-end latent space models, reducing the reliance on multi-stage pipelines that require manual feature engineering. For the broader AI industry, this means more efficient models that are less prone to the artifacts and "robotic" sounds often created by traditional vocoders. Furthermore, the advancement in zero-shot capabilities opens new doors for highly personalized digital assistants, more efficient localized content creation, and immersive human-computer interactions. LongCat-AudioDiT sets a new benchmark for fidelity and efficiency in the rapidly growing field of generative speech.
Frequently Asked Questions
Question: What is the main difference between LongCat-AudioDiT and traditional TTS models?
Traditional TTS models typically convert text into an intermediate visual representation called a Mel-spectrogram before turning it into sound waves. LongCat-AudioDiT removes this intermediate step, performing the synthesis directly in the waveform latent space using a diffusion model to avoid the errors that occur during these data conversions.
Question: How does this model improve zero-shot voice cloning?
By operating directly in the waveform latent space, the model can capture the inherent laws and patterns of sound more accurately. This eliminates "cascade errors" that accumulate in multi-stage systems, allowing the AI to replicate a unique voice more precisely from a very small sample without needing to be specifically trained on that individual's voice.
Question: Why did the Meituan team decide to abandon Mel-spectrograms?
The team identified Mel-spectrograms as a source of technical bottlenecks and data loss. By bypassing these intermediate representations, they aimed to create a more direct path for the AI to learn sound, resulting in higher fidelity, fewer artifacts, and a more robust performance in complex voice cloning tasks.