Understanding SWE-Explore: A New Benchmark for How AI Coding Agents Navigate and Explore Complex Repositories
The emergence of SWE-Explore marks a significant milestone in the evolution of autonomous software engineering. As AI coding agents increasingly struggle with the complexity of large-scale codebases—often becoming 'lost' during the navigation process—the industry has identified a critical need for standardized evaluation. SWE-Explore addresses this by benchmarking the specific exploration capabilities of these agents. This analysis delves into the challenges of repository navigation, the necessity of specialized benchmarks for exploration rather than just code generation, and how SWE-Explore provides a framework for measuring an agent's ability to locate, understand, and interact with files across vast repositories. By focusing on the 'exploration' phase of the software engineering lifecycle, this benchmark aims to bridge the gap between simple code completion and true autonomous engineering.
Key Takeaways
- Addressing Navigation Failures: SWE-Explore is designed to solve the problem of coding agents getting lost or becoming inefficient when tasked with navigating large, multi-file repositories.
- Focus on Exploration: Unlike traditional benchmarks that focus solely on code generation, SWE-Explore specifically targets the 'exploration' phase of the software engineering process.
- Standardized Benchmarking: The framework provides a structured method to measure how effectively an agent can find relevant information within a complex codebase.
- Improving Agent Autonomy: By identifying bottlenecks in repository navigation, the benchmark helps developers build more robust and autonomous AI software engineers.
In-Depth Analysis
The Challenge of Repository Navigation
The primary question posed by recent developments in AI software engineering is why coding agents frequently fail when introduced to large-scale repositories. In a localized environment, such as a single file or a small project, most modern Large Language Models (LLMs) demonstrate high proficiency in code generation and bug fixing. However, as the scope of the project grows to include thousands of files and complex dependency graphs, the performance of these agents often degrades.
This degradation is primarily attributed to the 'exploration' problem. An agent cannot fix a bug or implement a feature if it cannot first locate the relevant logic within a massive directory structure. When agents 'get lost,' they often enter loops of redundant file reads, fail to identify cross-file dependencies, or exhaust their context windows with irrelevant information. SWE-Explore addresses this specific bottleneck by isolating the exploration task from the implementation task, allowing researchers to see exactly where the navigation logic breaks down.
Benchmarking the Exploration Process
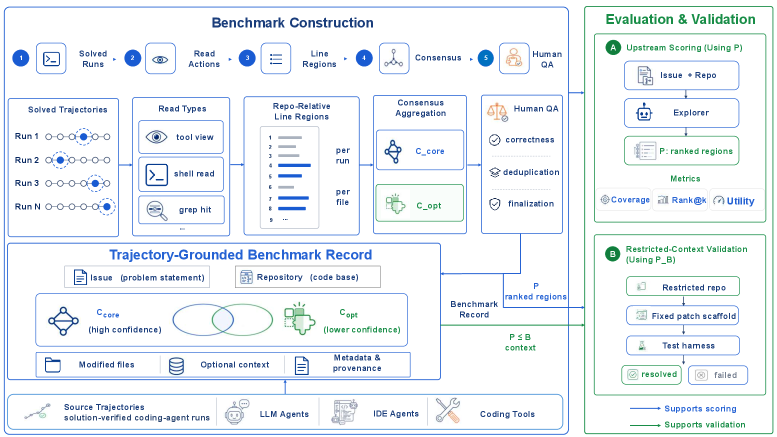
SWE-Explore introduces a specialized benchmarking environment that focuses on the trajectory of an agent's search. Traditional benchmarks like SWE-bench often look at the final output—whether the pull request passed the tests. While useful, this 'black box' evaluation does not explain why an agent failed. Did it fail because it couldn't write the code, or because it never found the right file to begin with?
By benchmarking the exploration process, SWE-Explore provides granular data on how agents interact with file systems. This includes measuring the efficiency of search queries, the relevance of the files opened, and the ability of the agent to build a mental map of the repository. This shift from 'outcome-based' evaluation to 'process-based' evaluation is essential for the next generation of AI agents that are expected to operate independently on professional-grade software projects.
Industry Impact
Setting New Standards for AI Software Engineers
The introduction of SWE-Explore is likely to shift the focus of the AI industry from raw model power to agentic workflow efficiency. As developers realize that simply increasing context window sizes is not a silver bullet for repository navigation, there will be a greater emphasis on building specialized tools and 'navigational heuristics' for agents. SWE-Explore provides the metric by which these new tools will be judged.
Accelerating Autonomous Development
For the AI industry, the ability to navigate repositories is the gatekeeper to true autonomy. If an agent can reliably explore a codebase, it can perform comprehensive audits, refactor legacy systems, and onboard itself to new projects without human intervention. By providing a benchmark for this specific skill, SWE-Explore accelerates the development of agents that can function as true 'teammates' rather than just sophisticated autocomplete tools. This will likely lead to a new wave of AI-native development environments designed specifically to assist agents in their exploration tasks.
Frequently Asked Questions
Question: What is the main purpose of SWE-Explore?
SWE-Explore is a benchmark designed to evaluate how effectively AI coding agents can navigate and explore large software repositories to find the information they need to solve tasks.
Question: Why do coding agents get lost in large repositories?
Agents often get lost due to the complexity of file structures, the lack of efficient search strategies, and the difficulty of maintaining a global understanding of a codebase within a limited context window.
Question: How does SWE-Explore differ from other coding benchmarks?
While many benchmarks focus on the final code output or bug-fixing success, SWE-Explore specifically measures the exploration and navigation phase, providing insight into how an agent searches through a codebase.